System Architecture and Configuration
System Hardware Specifications
PARAM Rudra system is based on the Intel Xeon Gold 6240R with a total peak performance of 3.1 PFLOPS. The cluster consists of compute nodes connected with the InfiniBand NDR Low-Latency, High-Bandwidth InfiniBand interconnect network. The system uses the Lustre parallel file system.
- Total number of Nodes: 622 (20 + 602)
-
Login Nodes: 10
-
Management Nodes: 10
-
CPU only Nodes: 482
-
GPU Nodes: 30
-
High Memory CPU only Nodes: 90
Login Nodes
Login nodes are typically used for administrative tasks such as editing, writing scripts, transferring files, managing your jobs and the like. You will always get connected to one of the login nodes. From the login nodes you can get connected to a Compute Node and execute an interactive job or submit batch jobs through the batch system (SLURM) to run your jobs on compute nodes. For all users PARAM Rudra Login Nodes are the entry points and hence are shared. By default, there will be a limit on the CPU time that can be used on a Login Node by a user and there is a limit/user on the memory as well. If any of these are exceeded, the job will get terminated.
| Login Nodes: | 10 |
|---|---|
| 2* Intel Xeon G-6240R Cores = 48, 2.4 GHz | Total Cores = 480 cores |
| Memory= 192 GB each | Total Memory = 1920 GB |
Service Nodes
PARAM Rudra is an aggregation of a large number of nodes connected through networks. Management nodes play a crucial role in managing and monitoring every component of PARAM Rudra cluster. This includes monitoring the health, load, and utilization of individual components, as well as providing essential services such as security, management, and monitoring to ensure the cluster functions smoothly.
| Management Nodes: | 8 |
|---|---|
| 2* Intel Xeon G-6240R Cores = 48, 2.4 GHz | Total Cores = 384 cores |
| Memory= 192 GB each | Total Memory = 1536 GB |
| Visualization Nodes: | 2 |
|---|---|
| 2* Intel Xeon G-6240R Cores = 48, 2.4 GHz | Total Cores = 96 cores |
| Memory= 192 GB each | Total Memory = 384 GB |
CPU Compute Nodes
CPU nodes are the individual machines dedicated to performing computational tasks. These nodes collectively form the computational power of the cluster. All the CPU intensive activities are carried on these nodes. Users can access these nodes from the login node to run interactive or batch jobs.
| CPU only Compute Nodes: | 482 |
|---|---|
| 2* Intel Xeon G-6240R Cores = 48, 2.4 GHz | Total Cores = 23136 cores |
| Memory= 192 GB each | Total Memory = 92544 GB |
| SSD | 800 GB local per node |
GPU Compute Nodes
GPU Compute Nodes feature accelerators cards that offer significant acceleration for parallel computing tasks using frameworks like CUDA and OpenCL. By harnessing the computational power of modern GPUs, these nodes are utilized for tasks such as scientific simulations, deep learning, and data analytics, providing high computational power and memory.
| GPU Compute Nodes: | 30 |
|---|---|
| 2* Intel Xeon G-6240R Cores = 48, 2.4 GHz | Total Cores = 1440 cores |
| Memory= 192 GB each | Total Memory = 5760 GB |
| SSD | 800 GB (local) per node |
| 2Nvidia A100 per node GPU Cores per node= 26912= 13824 | |
| GPU Memory = 80 GB HBM2e per Nvidia A100 |
High Memory Compute Nodes
High Memory Compute nodes are specialized nodes designed to handle workloads that require a large amount of memory.
| High memory Compute Nodes: | 90 |
|---|---|
| 2* Intel Xeon G-6240R Cores = 48, 2.4 GHz | Total Cores = 4320 cores |
| Memory= 768 GB each | Total Memory = 69120 GB |
| SSD | 800 GB (local) per node |
Storage
- Based on Lustre parallel file system
- Total useable capacity of 4.4 PiB Primary Storage
- Throughput 100 GB/s
PARAM Rudra Architecture Diagram

Figure 1 - PARAM Rudra Architecture Diagram
Operating System
The operating system on PARAM Rudra is Linux – Alma 8.9
Network infrastructure
A robust network infrastructure is essential for implementing the basic functionalities of a cluster. These functionalities include:
-
Management functionalities, such as monitoring, troubleshooting, starting and stopping various components of the cluster. The network/ or portion of the network that implements this functionality is referred to as the Management fabric.
-
Ensuring fast read/ writes access to the storage, the network or portion of the network that implements this functionality is referred to as the storage fabric.
-
Ensuring fast I/O operations, such as connecting to other clusters and connecting the cluster to various users on the campus LAN. The network or portion of the network that implements this functionality is referred to as the I/O Fabric.
-
Ensuring High-Bandwidth, Low-latency communication among processors is essential for achieving high-scalability. The network or portion of the network that implements this functionality is referred to as Message Passing Fabric.
Technically, all the above functionalities can be implemented in a single network. However, for optimal performance, economic suitability, and meeting specific requirements, these functionalities are implemented using two different networks based on different technologies, as explained below:
Primary Interconnection Network
InfiniBand: NDR
Computing nodes of PARAM Rudra are interconnected by a high-bandwidth, low-latency interconnect network, specifically InfiniBand: NDR. InfiniBand, a high-performance communication architecture owned by Mellanox, offers low communication latency, low power consumption and a high throughput. All CPU nodes are connected via the InfiniBand interconnect network.
Secondary Interconnection Network
Gigabit Ethernet: 10 Gbps
Gigabit Ethernet is the most commonly available interconnection network. No additional modules or libraries are required for Gigabit Ethernet. Both Open MPI, MPICH implementations will work over Gigabit Ethernet.
Software Stack
Software Stack is an aggregation of software components that work together to accomplish various tasks. These tasks can range from facilitating users in executing their jobs to enabling system administrators to manage the system efficiently. Each software component within the stack is equipped with the necessary tools to achieve its specific task, and there may be multiple components of different flavors for different sub-tasks. Users have the flexibility to mix and match these components according to their preferences. For users, the primary focus is on preparing executables, executing them with their datasets, and visualizing the output. This typically involves compiling codes, linking them with communication libraries, math libraries, and numerical algorithm libraries, preparing executables, running them with desired datasets, monitoring job progress, collecting results, and visualizing output. System administrators, on the other hand, are concerned with ensuring optimal resource utilization. To achieve this, they may require installation tools, health-check tools for all components, efficient schedulers, and tools for resource allocation and usage monitoring. The software stack provided with this system has a wide range of software components that meet the needs of both users and administrators.
Figure 2 illustrates the components of the software stack.
C-CHAKSHU, a multi-cluster management tool designed to help administrators operate the HPC facility efficiently. It also enables the users to monitor system metrics relating to CPU, storage, interconnects, file system and application-specific utilization from a single dashboard. For more information, please follow the link: https://paramrudra.iitb.ac.in/chakshu-front
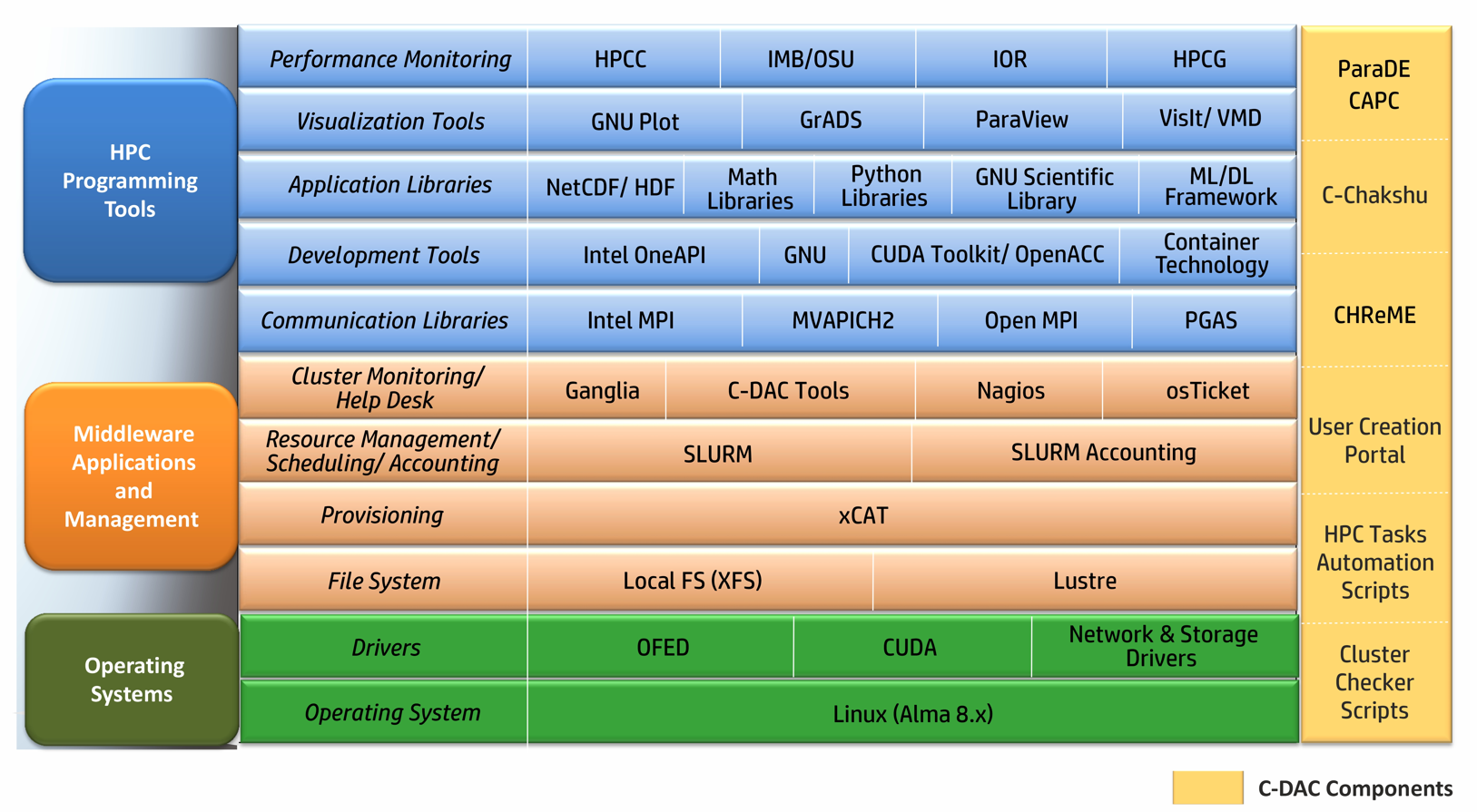
Figure 2 - Software Stack
| Functional Areas | Components |
| Base OS | Alma 8.9 |
| Architecture | X86_64 |
| Provisioning and Cluster Manager |
xCAT 2.16.5 |
| Monitoring Tools | C-CHAKSHU, Nagios, Ganglia |
| Resource Manager | SLURM- 23.11.10 |
| I/O Services | Lustre Client |
| High Speed Interconnects | Mellanox InfiniBand (MLNX_OFED_LINUX-23.10) |
| Compiler Families | GNU (gcc, g++, GNU Fortran) Intel Compiler (icc, ifort, icpc) |
| MPI Families | MVAPICH, Open MPI, MPICH |